Video Overview
Abstract
We present Playable Environments - a new representation for interactive video generation and manipulation in space and time. With a single image at inference time, our novel framework allows the user to move objects in 3D while generating a video by providing a sequence of desired actions. The actions are learnt in an unsupervised manner. The camera can be controlled to get the desired viewpoint. Our method builds an environment state for each frame, which can be manipulated by our proposed action module and decoded back to the image space with volumetric rendering. To support diverse appearances of objects, we extend neural radiance fields with style-based modulation. Our method trains on a collection of various monocular videos requiring only the estimated camera parameters and 2D object locations. To set a challenging benchmark, we introduce two large scale video datasets with significant camera movements. As evidenced by our experiments, playable environments enable several creative applications not attainable by prior video synthesis works, including playable 3D video generation, stylization and manipulation.
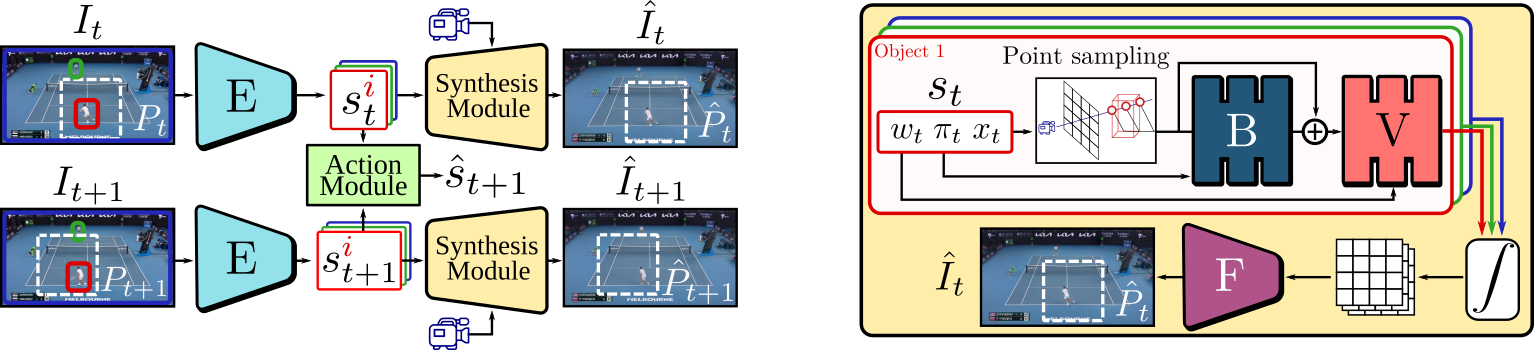
Overview
Our method consists of two components. The first one is the synthesis module. It extracts the state of the environment - location, style and non-rigid pose of each object - and renders the state back to the image space. Recently introduced Neural Radiance Fields (NeRFs) represent an attractive tool for their ability to render novel views. We propose a compositional non-rigid volumetric rendering approach handling the rigid parts of the scene and non-rigid objects with support for different visual styles. The second component - the action module - enables playability. It takes two consecutive states of the environment and predicts an action with respect to the camera orientation that is used to reconstruct the subsequent environment state.
Video Manipulation Results
Given a single initial frame, our method creates playable environments that allow the user to interactively generate different videos by specifying discrete actions to control players, manipulating camera trajectory and indicating the style for each object in the scene.