Video Overview
BAIR
Atari Breakout
Tennis
Abstract
This paper introduces the unsupervised learning problem of playable video generation (PVG). In PVG, we aim at allowing a user to control the generated video by selecting a discrete action at every time step as when playing a video game. he difficulty of the task lies both in learning semantically consistent actions and in generating realistic videos conditioned on the user input. We propose a novel framework for PVG that is trained in a self-supervised manner on a large dataset of unlabelled videos. We employ an encoder-decoder architecture where the predicted action labels act as bottleneck. The network is constrained to learn a rich action space using, as main driving loss, a reconstruction loss on the generated video. We demonstrate the effectiveness of the proposed approach on several datasets with wide environment variety.
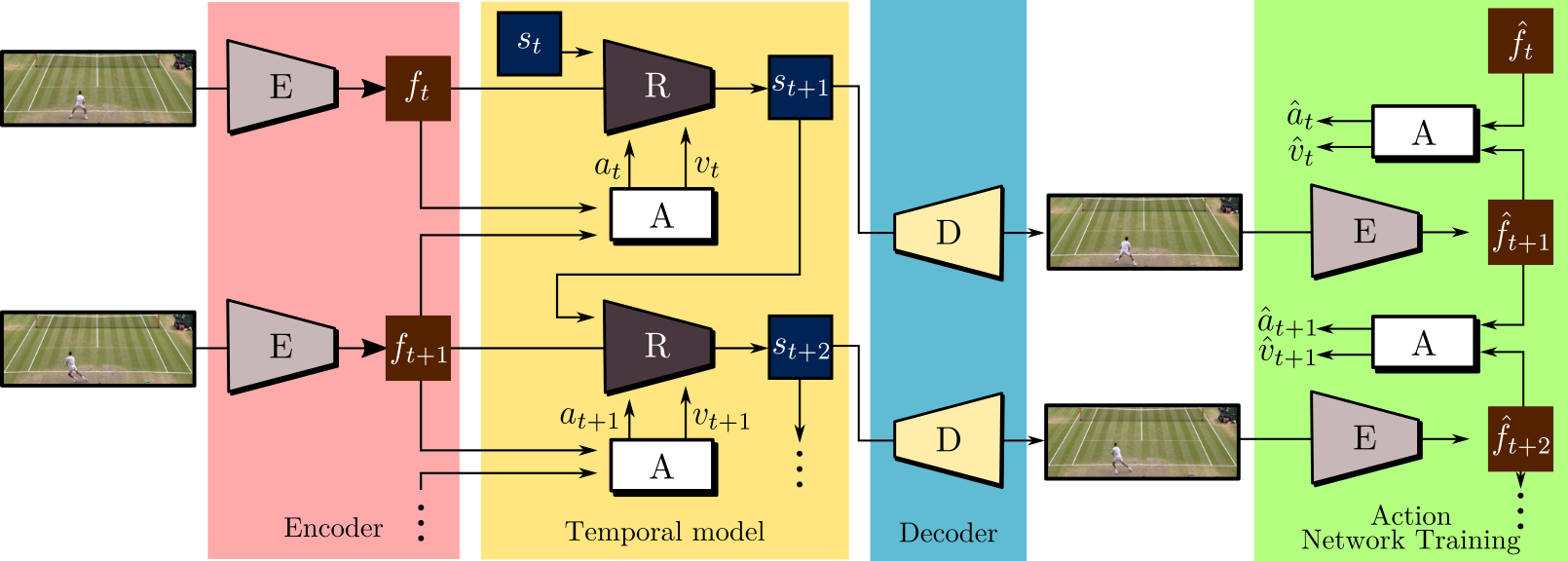
Overview
Given a set of completely unlabeled videos, we jointly learn a set of discrete actions and a video generation model conditioned on the learned actions. At test time, the user can control the generated video on-the-fly providing action labels as if he or she was playing a videogame. We name our method CADDY. Our architecture for unsupervised playable video generation is composed by several components. An encoder E extracts frame representations from the input sequence. A temporal model estimates the successive states using a recurrent dynamics network R and an action network A which predicts the action label corresponding to the current action performed in the input sequence. Finally, a decoder D reconstructs the input frames. The model is trained using reconstruction as the main driving loss.
Results
CADDY automatically discovers the most significant actions to condition video generation and can produce playable video generation models in a variety of settings, from videogames to real videos. We test our model on the BAIR dataset, Atari Breakout and a Tennis dataset. Each action captures a specific behavior and action meaning is consistently maintained.